
The race for computational power to drive Artificial Intelligence has turned the hardware sector into an intense, high-stakes battleground. Leading the charge is NVIDIA, which recently approached a $4 trillion market capitalization.
NVIDIA maintains a significant advantage with its mature CUDA ecosystem. CUDA is a programming platform that enables developers to efficiently harness GPU power, and nearly all major AI frameworks, including PyTorch and TensorFlow, are deeply optimized for it. This comprehensive, battle-tested software stack dramatically reduces development time and effectively locks in the developer community.
However, Cerebras co-founder Andrew Feldman argues that CUDA’s strength in today’s AI landscape is becoming a weakness, especially regarding the cost and efficiency of AI inference (Source: 20VC with Harry Stebbings).
Founding Story of Cerebras
Cerebras was founded by chip industry veterans with a strong track record. Its five co-founders previously worked together at SeaMicro, which was later acquired by AMD in 2012.
The company is built on the belief that traditional chip design is fundamentally inefficient. By creating the largest chip in the world, the Wafer-Scale Engine (WSE), Cerebras aims to deliver far greater efficiency for AI training and inference than conventional GPU clusters.
The WSE-3 measures 72 square inches and offers 50 times the compute power of Nvidia’s H100 GPU. By comparison, the H100 is only 1 square inch and contains 80 billion transistors (Source: WTW)

Cerebras WSE 3 Vs NVIDIA H100, Photo credit: servethehome.com
How Do LLMs Work?
GPT stands for “Generative Pre-trained Transformer,” a type of Large Language Model (LLM) designed to understand and generate human-like text. It is:
Generative because it creates new content
Pre-trained because it is trained on massive text datasets
Transformer-based because it uses the transformer architecture, a neural network design that excels at handling sequential data
The Transformer architecture, both Encoder and Decoder, is essentially a pipeline of highly parallel, repetitive matrix multiplications.
The core goal of AI chip design is to find more efficient ways to run these transformer operations.
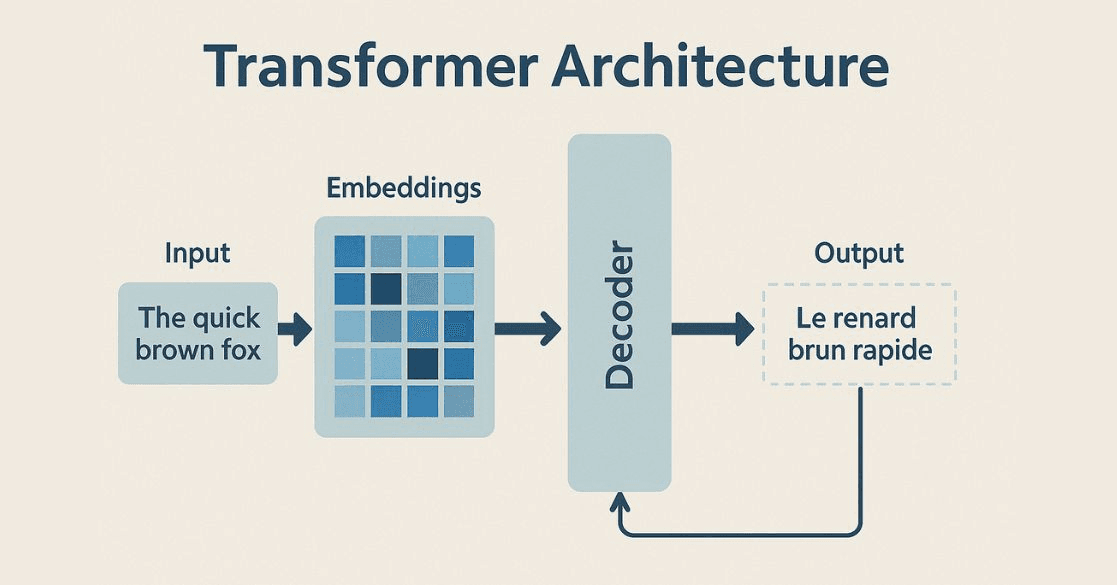
Photo credit: mygreatlearning.com
GPU Limitations for Transformers
NVIDIA dominates the AI hardware world with its GPUs (Graphics Processing Units). But GPUs were originally designed to be general-purpose parallel processors, not transformer-optimized engines.
Transformers require repetitive, specialized math. By contrast, GPUs include many components (graphics units, texture units, etc.) that are underutilized for AI workloads. A significant portion of GPU silicon, designed for graphics, is essentially wasted on transformer computation.
Memory bandwidth is another major issue. Transformers are often bottlenecked by memory movement, especially during decoding. Performance is limited by the speed at which model weights and the KV cache can be streamed from high-bandwidth memory to compute cores.
Cerebras’ Advantage
Feldman argues that AI has not “hit scaling laws.” Instead, he believes current limits stem from inefficient algorithms and poorly optimized hardware.
Cerebras and other players are developing Application-Specific Integrated Circuits (ASICs) purpose-built for transformer workloads (Source: 20VC podcast). Google has also entered the space with its Tensor Processing Unit (TPU) (Source: CNBC). These chips devote the majority of their transistors to efficient matrix-multiplication units, removing the general-purpose overhead found in GPUs.
The WSE-3 also includes massive on-chip memory with unprecedented bandwidth, enabling faster data access and reducing bottlenecks that plague distributed GPU systems.
These advantages make Cerebras systems well-suited for training large AI models and handling complex, data-intensive workloads. For example, training a 175-billion-parameter model on 4,000 GPUs might require 20,000 lines of code, whereas Cerebras can accomplish the same with just 565 lines, in one day (Source: sacra.com).
Targeting Supercomputer Performance
Cerebras has found product-market fit across several sectors:
Government & Research: Cerebras systems run in multiple U.S. Department of Energy (DOE) national laboratories and support national security, scientific research, and energy innovation. Several governments are investing in Cerebras technology for sovereign clouds to meet domestic AI requirements.
Healthcare & Life Sciences: Customers such as GlaxoSmithKline use Cerebras for epigenomics research, while Mayo Clinic employs the systems to advance diagnostics and personalized medicine.
Energy & Finance: TotalEnergies, a $100 billion French energy company, is a notable customer. Cerebras also works with financial institutions on complex modeling and risk assessment.
Cerebras’s Milestones
Cerebras has achieved several notable milestones in recent years:
March 2024: Unveiled the Wafer-Scale Engine 3 (WSE-3), claimed to be the fastest AI chip on Earth. (Source: Microventures)
January 2024: Signed a multi-million-dollar agreement with Mayo Clinic to develop AI models for healthcare. (Source: Microventures)
December 2023: Forbes reported that Cerebras’ revenue and customer commitments were nearing $1 billion. (Source: Forbes)
2023–2024 Revenue Growth: Revenue grew from $78.7 million in 2023 to an estimated $500 million in 2024 - massive acceleration. (Source: sacra.com)
Cerebras vs. Other Players in AI Chip Market
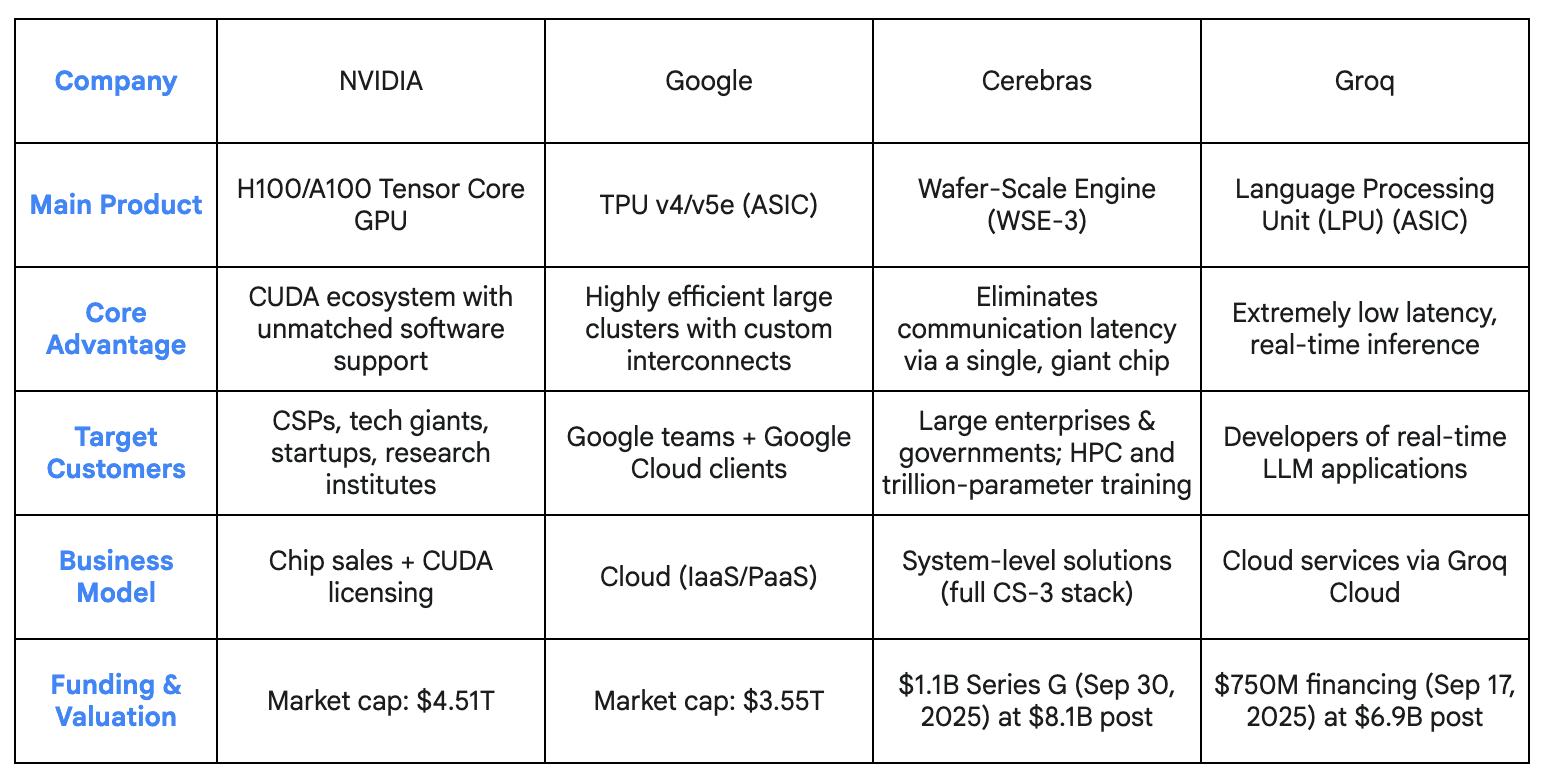
The Battle for the Next Silicon Generation
NVIDIA currently holds an overwhelming ~80% market share, protected by the ubiquity of CUDA, which ensures nearly all new AI models run best on its hardware.
However, scaling economics and efficiency demands are starting to challenge this dominance. GPU design, optimized for general-purpose parallelism, faces growing strain due to limited memory bandwidth and the high cost of data movement. These factors expose the inefficiencies of GPUs for extremely large and specific workloads, posing a moderate threat to NVIDIA’s hardware advantage.
Startups such as Cerebras and Groq are targeting these weaknesses directly, offering compelling price-performance improvements in specialized niches through ASIC-based architectures.
NVIDIA is countering by doubling down on its software moat, enhancing tools like NeMo and TensorRT, to extract more performance from its hardware and keep developers locked into the CUDA ecosystem.
NVIDIA remains the indispensable core of AI infrastructure, but the industry is shifting from general-purpose power to specialized efficiency. The coming years will feature an intense race between revolutionary hardware advances and a dominant, adaptive software ecosystem, ultimately leading to faster, cheaper, and more accessible AI for everyone.



